Ching-I Huang1, Yu-Yen Huang1, Jie-Xin Liu1, Yu-Ting Ko1, Hsueh-Cheng Wang*,1,
Kuang-Hsing Chiang2,3,4,5, Lap-Fai Yu6
________________________________________________
1National Yang Ming Chiao Tung University (NYCU), Taiwan.
2Taipei Heart Institute, Taipei Medical University, Taipei, Taiwan.
3Division of Cardiology and Cardiovascular Research Center, Taipei Medical University Hospital, Taipei, Taiwan.
4Department of Internal Medicine, School of Medicine, College of Medicine, Taipei Medical University, Taipei, Taiwan.
5Graduate Institute of Biomedical Electronics and Bioinformatics, National Taiwan University, Taipei, Taiwan.
6Department of Computer Science, George Mason University, USA.
Abstract
Human-robot handover is a key capability of service robots, such as those performing routine logistical tasks for healthcare workers. Recent visual grasping algorithms have achieved tremendous advances in object-agnostic end-to-end planar grasping with up to six degrees of freedom (DoF); however, compiling the requisite datasets is infeasible in many situations and the use of camera feeds would be considered invasive in other situations. In this study, we proposed Fed-HANet, trained with the framework of federated learning, to achieve a privacy-preserving end-to-end control system for 6-DoF visual grasping of unseen objects. The federated learning approach showed accuracy close to that of centralized, non-privacy- preserving systems or other baseline methods using fine-tuning. Our proposed model was compared to several existing methods, and an ablation study was performed using depth-only inputs. The practicality of Fed-HANet in robotic systems was assessed in a user study involving 12 participants. The dataset for training and all pretrained models are available at https://arg-nctu.github.io/projects/fed-hanet.html.
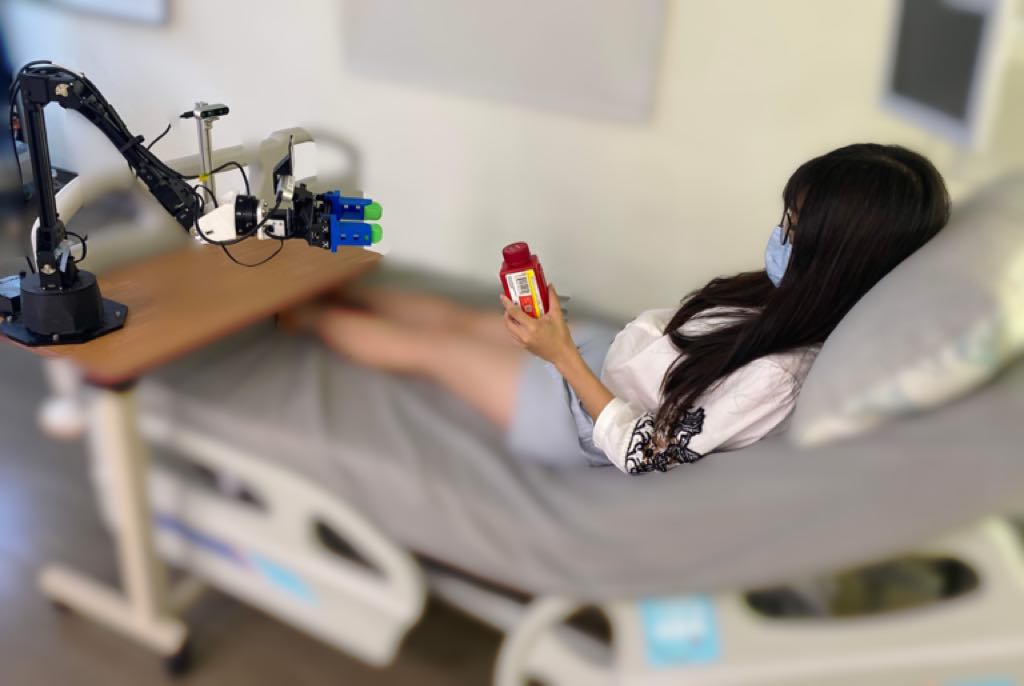
Video
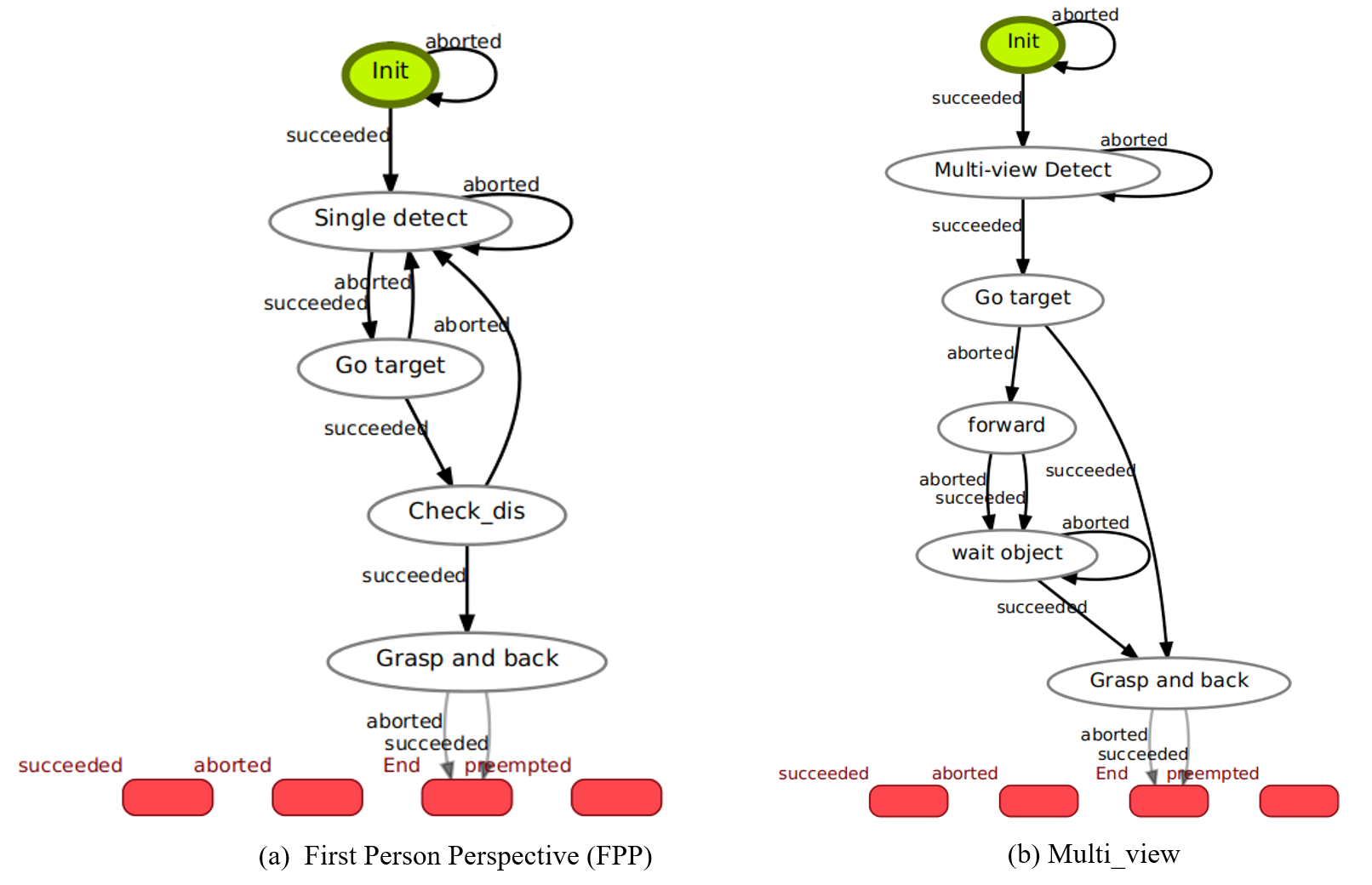
Appendix A: Human-to-Robot Handover Workflows
The state machines by Smach viewer for First Person Perspective (FPP; closed-loop) and Multi-View (MV).
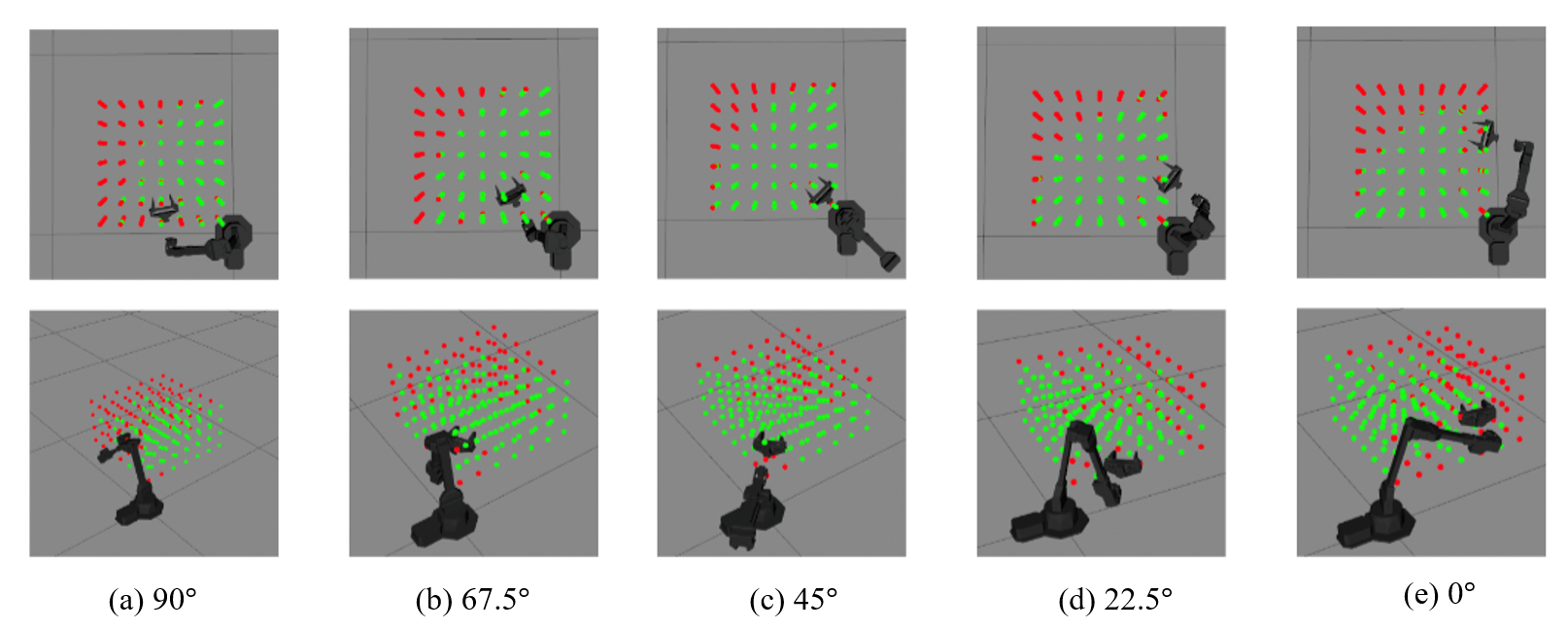
Appendix B: Reachable Grasping Points of MV
The predicted grasping positions for different angle from 90 degree to 0 degree calculated every 22.5 degrees.
Appendix C: Comparisions of RGB-D and Depth-Only Inputs
Testing Dataset HANet-Upright

Testing Dataset HANet-Rotated

Appendix D: Handover Datasets
Object sets used in (a) training set, (b) testing set, and (c) user study. Note that some objects are only graspable from one side due to the limited width between two fingers of the gripper in the system.

Appendix E: Grasping prediction
Visualizations of grasping prediction on the 4 testing datasets. Each grasp was visualized as a line segment. The center point of the segment was the top-1 accuracy of grasp prediction; both ends represented the positions of the two fingers at the open state of the gripper. (width of the open gripper: 8 cm)
